
핀아의 저장소 ( •̀ ω •́ )✧
01_06. Reduction Operations 본문
Reduction
- 요소들을 모아서 하나로 합치는 작업
- 많은 Spark의 연산들이 reduction이다.
✅ Parallel Transformations
- 주로 변형을 적용시키는 작업들
- map, flatMap, filter
✅ 그렇다면 Action은 어떻게 분산된 환경에서 작동할까?
- 대부분의 Action은 Reduction이다.
- Reduction: 근접하는 요소들을 모아서 하나의 결과로 만드는 일
- 파일 저장, collect()등과 같이 Reduction이 아닌 액션도 있다.
✅ 병렬처리
- 병렬처리 하려면 두개의 요소를 모아서 하나로 만들 수 있어야 한다.

- 하지만, 파티션마다 독립적으로 있지 않고 파티션마다 의존적이면 병렬처리 불가능하다.
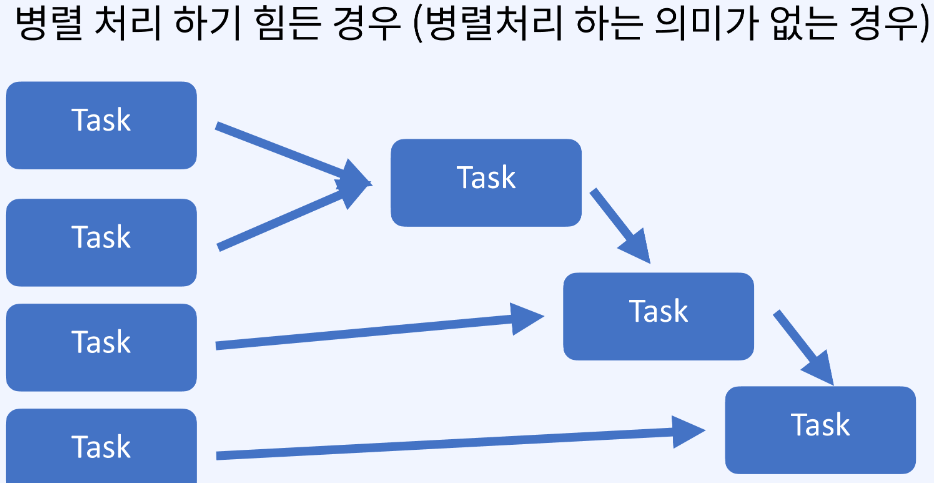
✅ 대표적인 Reduction Actions
- Reduce
- Fold
- GroupBy
- Aggregate
1️⃣ Reduce
- RDD.reduce(<function>)
- 사용자의 데이터 값을 하나로 만들어준다.
from operator import add
sc.parallelize([1, 2, 3, 4, 5]).reduce(add) # 15- 하지만 파티션에 따라 결과 값이 달라지게 되므로 분산된 파티션들의 연산과 합치는 부분을 나눠서 생각해야 한다.

- 하지만 파티션이 어떻게 나뉠지 프로그래머가 정확하게 알기 어려우므로 법칙을 기억해야 한다.
- 교환법칙 (a*b=b*a)
- 결합법칙 (a*b)*c=a*(b*c)
2️⃣ Fold
- RDD.fold(zeroValue, <function>)
from operator import add
sc.parallelize([1, 2, 3, 4, 5]).fold(0, add) # 15- reduce와 똑같은 기능을 하지만 다른점은 zerovalue가 추가된다.
- zerovalue란 각 파티션에서 누적할 시작값을 뜻한다.


3️⃣ GroupBy
- RDD.groupBy(<기준 함수>)
rdd = sc.parallelize([1, 1, 2, 3, 5, 8])
result = rdd.groupBy(lambda x: x % 2).collect()
sorted([x, sorted(y)) for (x, y) in result])
# [(0, [2, 8]), (1, [1, 1, 3, 5])]- RDD 내의 데이터를 기준에 따라 여러개의 그룹으로 나눠주는 역할을 한다.
4️⃣ Aggregate
- RDD 데이터 타입과 Action 결과 타입이 다를 경우 사용
- 파티션 단위의 연산 결과를 합치는 과정을 거친다.
- RDD.aggregate(zeroValue, seqOp, combOp)
- zeroValue: 각 파티션에선 누적할 시작 값
- seqOp: 타입 변경 함수
- combOp: 합치는 함수
- 많이 쓰이는 reduction action
- 대부분의 데이터 작업은 크고 복잡한 데이터 타입 -> 정제된 데이터

✅ Key-Value RDD Reduction
- 배운것 외에도 여러가지 Operation이 존재
- Key-Value RDD
- groupByKey
- reduceByKey
'Big Data > Engineering' 카테고리의 다른 글
| 01_08. Shuffling & Partitioning (0) | 2023.05.14 |
|---|---|
| 01_07. Key-Value RDD Operations & Joins (0) | 2023.05.14 |
| 01_05. Cluster Topology (1) | 2023.05.13 |
| 01_04. Cache & Persist (0) | 2023.05.13 |
| 01_03. RDD Transformations and Actions (2) | 2023.05.13 |
'Big Data/Engineering' Related Articles
more




Comments