
핀아의 저장소 ( •̀ ω •́ )✧
02_04. DataFrame 본문
✅ DataFrame은 관계형 데이터
- 한마디로 관계형 데이터셋: RDD + Relation
- RDD가 함수형 API를 가졌다면 DataFrame은 선언형 API
- 자동으로 최적화가 가능
- 타입이 없다 -> DataFrame은 내부적으로 타입을 강제하지 않는다.
✅ DataFrame의 특징
DataFrame: RDD의 확장판
- 지연 실행 (Lazy Execution)
- 분산 저장
- Immutable
- 열 (Row) 객체가 있다
- SQL 쿼리를 실행할 수 있다
- 스키마를 가질 수 있고 이를 통해 성능을 더욱 최적화 할 수 있다.
- CSV, JSON, Hive 등으로 읽어오거나 변환이 가능하다.
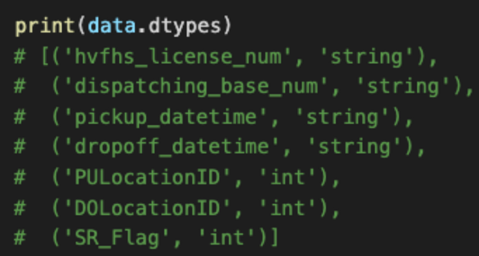
✅ DataFrame의 스키마를 확인하는 법
- dtypes
- show()
- 테이블 형태로 데이터를 출력
- 첫 20개의 열만 보여준다
- printSchema()
- 스키마를 트리 형태로 볼 수 있다.


✅ 복잡한 DataType들
- ArrayType
- MapType -> dictionary
- StructType -> object
✅ DataFrame Operations
SQL과 비슷한 작업이 가능하다
- Select
- Where
- Limit
- OrderBy
- GroupBy
- Join
1️⃣ select
- 사용자가 원하는 Column이나 데이터를 추출 하는데 사용

- DataFrame도 Lazy Execution이므로 collect()로 불러줘야 함
- 두 번째의 경우 사용자가 원하는 ‘name’과 ‘age’를 select를 하여 데이터 추출
2️⃣ Agg
- Aggregate의 약자로, 그룹핑 후 데이터를 하나로 합치는 작업

- 두 번째 실행문의 경우 함수와 컬럼을 지정하여 첫 번째와 똑같은 효과를 낼 수 있음
3️⃣ GroupBy
- 사용자가 지정한 Column을 기준으로 데이터를 Grouping하는 작업

4️⃣ Join
- 다른 DataFrame과 사용자가 지정한 Column을 기준으로 합치는 작업

✅ DataFrame 조작하기
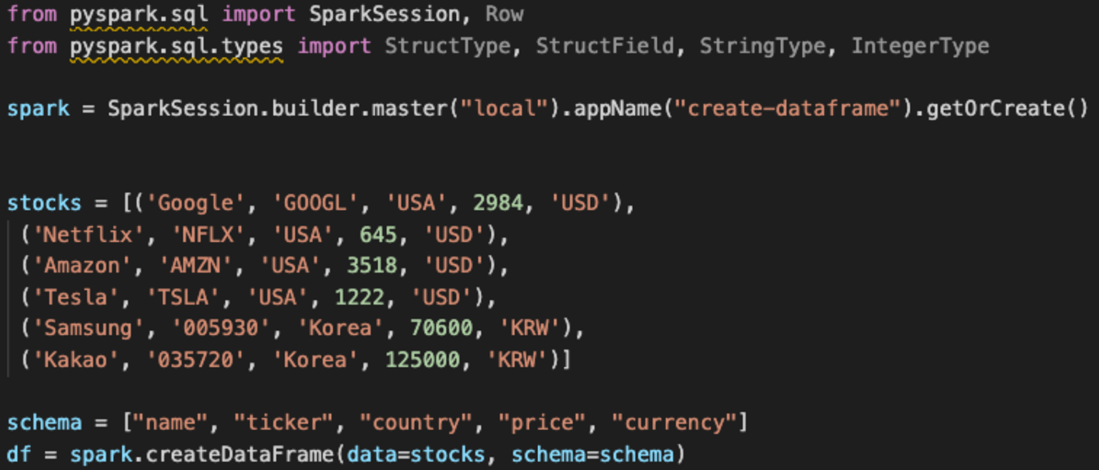
- stocks 내 4번째 데이터는 숫자값이기 때문에 다른값들과는 다르게 integer값으로 schema가 지정된다.


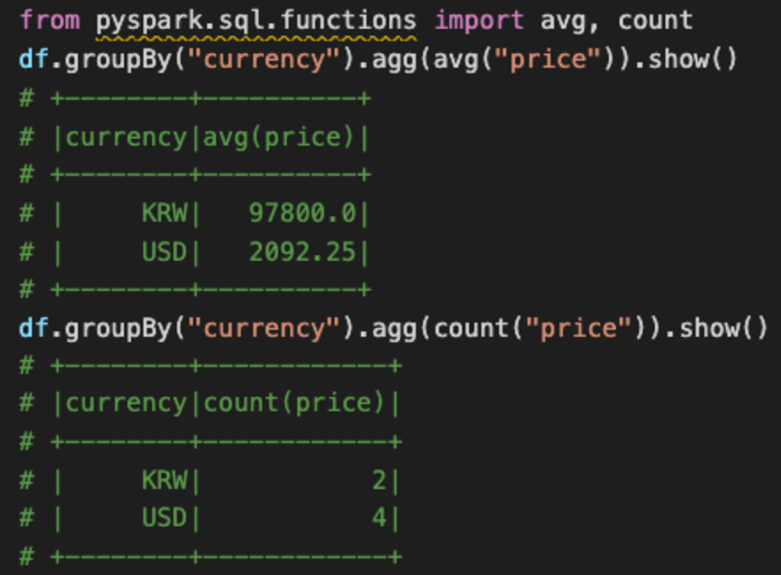
- ‘currency’값을 기준으로 grouping 해주고 가격 평균 출력과 각 나라별 주식 개수 출력
'Big Data > Engineering' 카테고리의 다른 글
| 02_03. SQL 기초 (0) | 2023.05.24 |
|---|---|
| 02_02. SparkSQL 소개 및 기초 (0) | 2023.05.14 |
| 02_01. Structured vs Unstructured Data (0) | 2023.05.14 |
| 01_08. Shuffling & Partitioning (0) | 2023.05.14 |
| 01_07. Key-Value RDD Operations & Joins (0) | 2023.05.14 |
'Big Data/Engineering' Related Articles
more




Comments