
핀아의 저장소 ( •̀ ω •́ )✧
6. 양방향 연결 리스트(Doubly Linked Lists) 본문
이 글은 "어서와! 자료구조와 알고리즘은 처음이지?" 강의를 듣고 정리한 내용입니다. 😉
지금까지의 연결 리스트에서는 링크가 한 방향으로, 즉 앞에서 뒤로, 다시 말하면 먼저 오는 데이터 원소를 담은 노드로부터 그 뒤에 오는 데이터 원소를 담은 노드를 향하는 방향으로만 연결되어 있었다. 이번에는 새로운 연결 리스트로서 양방향 연결 리스트 (doubly linked list) 를 살펴보고자 한다.
말 그대로, 양방향 연결 리스트에서는 노드들이 앞/뒤로 연결되어 있다. 즉, 인접한 두 개의 노드들은 앞의 노드로부터 뒤의 노드가 연결되어 있을뿐만 아니라, 뒤의 노드로부터 앞의 노드도 연결되어 있다.
한 노드의 입장에서 보자면, 자신보다 앞에 오는 노드를 연결하는 링크와 자신보다 뒤에 오는 노드를 연결하는 링크를 둘 다 가지므로 모든 연결은 양방향으로 이루어져 있으며, 그러한 이유로 이런 구조의 연결 리스트를 "양방향 연결 리스트" 라고 부른다.
양방향 연결 리스트는 단방향 연결 리스트에 비해서 어떤 단점을 가질까? 당연히, 링크를 나타내기 위한 메모리 사용량이 늘어난다. 또한, 원소를 삽입/삭제하는 연산에 있어서 앞/뒤의 링크를 모두 조정해 주어야 하기 때문에 프로그래머가 조금 더 귀찮아진다. 그럼에도 불구하고 왜 양방향 연결 리스트를 이용할까?
양방향 연결 리스트가 단방향 연결 리스트에 비해서 가지는 장점은, 데이터 원소들을 차례로 방문할 때, 앞에서부터 뒤로도 할 수 있지만 뒤에서부터 앞으로도 할 수 있다는 점이다.
앞 강에서 했던 것과 마찬가지로, 동일한 모습의 연산을 일관되게 적용하기 위해서는 양방향 연결 리스트의 맨 앞과 맨 뒤에 더미 노드 (dummy node) 를 하나씩 추가할 수 있다. 링크를 앞/뒤로 두고, 더미 노드도 맨 앞과 맨 뒤에 두고, 점점 리스트의 모습이 복잡해져 가는 것처럼 느껴질 수 있지만 이렇게 함으로써 오히려 리스트를 대상으로 하는 연산들이 깔끔하게 구현될 수 있다는 장점이 있다. 특별한 경우로 처리해야 하는 것들이 없어지기 (줄어들기) 때문이다.
양방향 연결 리스트(Doubly Linked Lists)
- 한 쪽으로만 링크를 연결하지 말고, 양쪽으로!
- → 앞으로도(다음 node), 뒤로도(이전 node) 진행 가능

노드의 확장
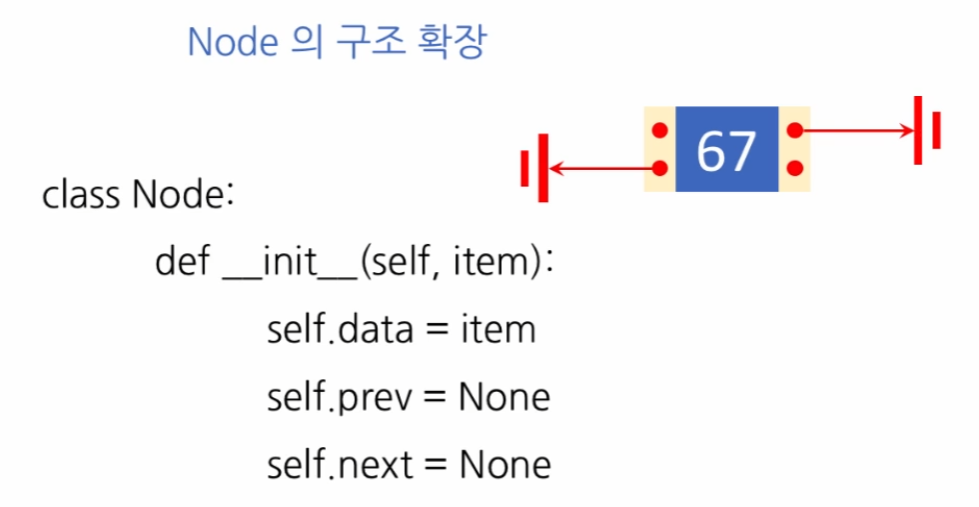
class Node:
def __init__(self, item):
self.data = item
self.prev = None
self.next = None- 리스트 처음과 끝에 dummy node를 두자 => 데이터를 담고 잇는 node들은 모두 같은 모양
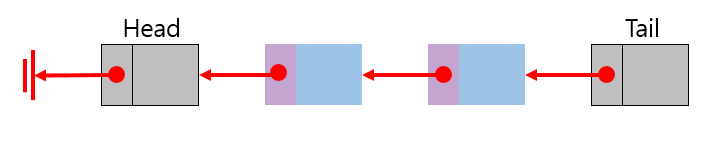
양방향 연결 리스트의 구조

- 리스트의 처음과 끝에 dummy node를 둔다.
- 데이터를 담고있는 node들이 모두 같은 모양이 된다.
- 코드를 작성하는데 있어 상당히 편안해지게 된다.

class DoublyLinkedList:
def __init__(self, item):
self.nodeCount = 0
self.head = Node(None)
self.tail = Node(None)
self.head.prev = None
self.head.next = self.tail
self.tail.prev = self.head
self.tail.next = None
연산 정의
- 특정 원소 참조(k 번째)
- 리스트 순회
- 리스트 역순회
- 원소 삽입
- 원소 삭제
- 두 리스트 병합
1️⃣ 특정 원소 참조
- 지난 연결 리스트(Linked List)와 동일
def getAt(self, pos):
if pos < 0 or pos > self.nodeCount:
return None
i = 0
curr = self.head
while i < pos:
curr = curr.next
i += 1
return curr
2️⃣ 리스트 순회


- while문 안에서 현재 노드의 다음.다음이 유효할 때까지 반복한다.
- 리스트가 비어있는 경우에서도 유효한 코드가 된다.
def traverse(self):
result = []
curr = self.head
while curr.next.next:
curr = curr.next
result.append(curr.data)
return result3️⃣ 리스트 역순회

def reverse(self):
result = []
curr = self.tail
while curr.prev.prev:
curr = curr.prev
result.append(curr.data)
return result4️⃣ 원소의 삽입

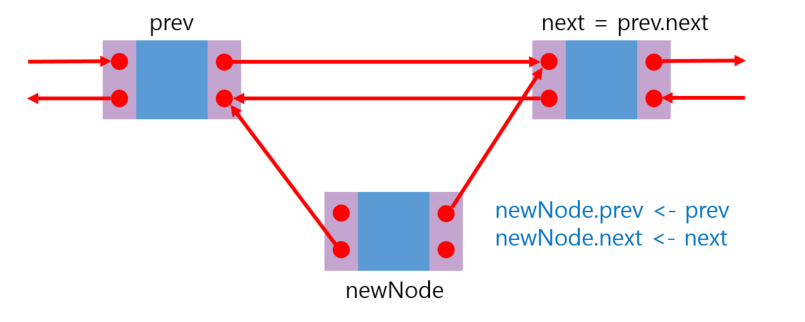


def insertAfter(self, prev, newNode):
next = prev.next
newNode.prev = prev
newNode.next = next
prev.next = newNode
next.prev = newNode
self.nodeCount += 1
return Truedef insertAt(self, pos, newNode):
if pos < 1 or pos > self.nodeCount + 1:
return False
prev = self.getAt(pos - 1)
return self.insertAfter(prev, newNode)
def insertBefore(self, next, newnode):
prev = next.prev
newNode.next = prev.next
newNode.prev = prev
prev.next = newNode
next.prev = newNode
self.nodeCount += 1
return True
리스트 마지막에 원소를 삽입하려면?
# 마지막 원소 삽입 수정 본 getAt()을 수정
# 특정 원소 얻어내기
def getAt(self, pos):
if pos < 0 or pos > self.nodeCount:
return None
# pos가 오른쪽으로 치우쳐있는 경우 tail쪽에서 계산
if pos > self.nodeCount // 2:
i = 0
curr = self.tail
while i < self.nodeCount - pos + 1:
curr = curr.prev
i += 1
# pos가 왼쪽으로 치우쳐 있는 경우 head에서 계산
else:
i = 0
curr = self.head
while i < pos:
curr = curr.next
i += 1
return curr- 특정 부분에 치우쳐저 있다면 반으로 나눠서 구하는게 낫다.
- 하지만 여전히 삽입 시에는 리스트의 길이가 길 수록 시간이 오래 걸리는 선형 시간 알고리즘임에는 변함 없다.
5️⃣ 원소의 삭제
def popAfter(self, prev):
curr = prev.next
prev.next = curr.next
curr.next.prev = prev
self.nodeCount -= 1
return curr.data
def popBefore(self, next):
curr = next.prev
next.prev = curr.prev
curr.prev.next = next
self.nodeCount -= 1
return curr.data
def popAt(self, pos):
if pos < 1 or pos > self.nodeCount:
raise IndexError
prev = self.getAt(pos - 1)
return self.popAfter(prev)6️⃣ 두 리스트의 병합
# 두 리스트의 병합
def concat(self, L):
self.tail.prev.next = L.head.next
L.head.next.prev = self.tail.prev
self.tail = L.tail
self.nodeCount += L.nodeCount'Computer Science > 자료구조' 카테고리의 다른 글
| 8. 스택의 응용 (0) | 2023.05.05 |
|---|---|
| 7. 스택(Stacks) (0) | 2023.05.04 |
| 5. 연결 리스트 (Linked Lists) (0) | 2023.05.01 |
| 4. 알고리즘의 복잡도 (Comlexity of Algorithms) (0) | 2023.04.30 |
| 3. 재귀 알고리즘 기초 및 응용 (0) | 2023.04.30 |



